RAG+ Evaluation System
Reduced information retrieval time by 85% while achieving 92% answer accuracy through a custom RAG system with advanced evaluation framework
92%
Precision
89%
Recall
85%
Time Saved
What I Built
RAG with dedicated Evaluation Framework - essential for validating system performance
Critical for unseen information - evaluation framework is especially important for data LLMs haven't encountered during training
Guarantees correctness - ensures results are accurate and reliable
Enables measurement and improvement - identifies failure points and failure rates to systematically enhance the system
The Challenge
Organizations struggle to extract insights from vast document repositories, with teams spending hours daily searching through technical documentation
Traditional keyword search misses 60% of relevant information due to semantic gaps, leading to duplicated work and missed opportunities.

Selecting a right approach
Imagine searching through hundreds of PDF documents to find one answer. Now imagine getting that answer in seconds, with sources cited.
Two-Stage Retrieval
Vector search + AI re-ranking for 40% better relevance
Custom Evaluation Framework
Precision, Recall, and MRR metrics for continuous improvement
Real-Time Q&A Interface
Source attribution with 3s avg response time
Production-Ready API
Modular design with scalable architecture
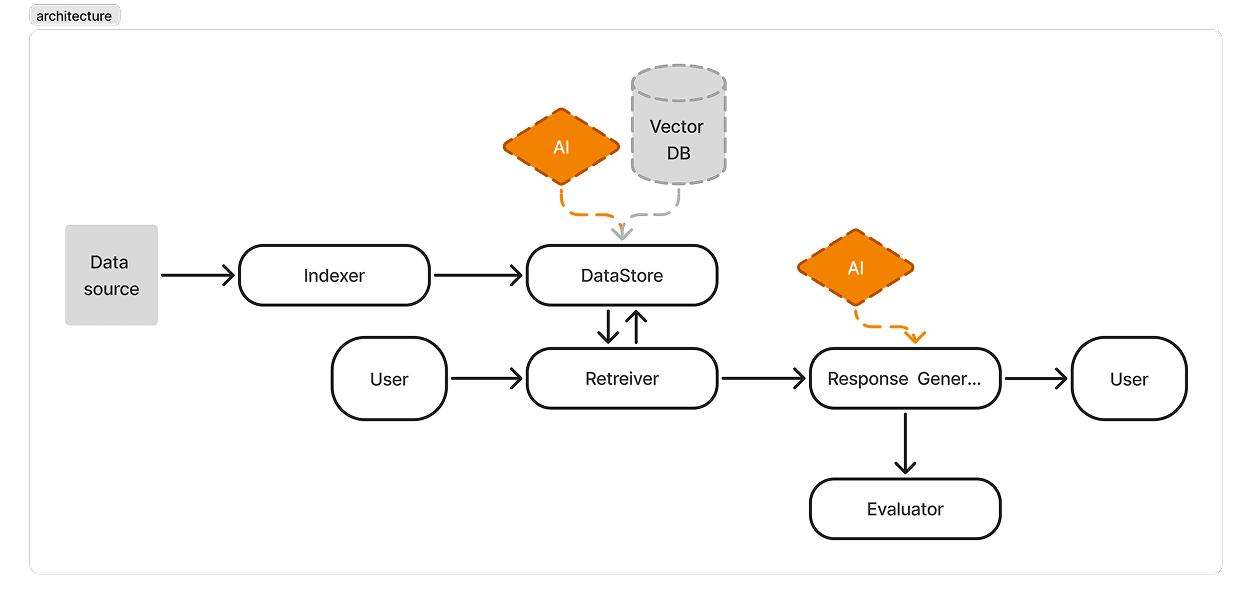
The Architecture
Understands what you're really asking (not just keywords), checks every relevant document instantly and brings you the best answers.
Smart Retrieval System
The system understands intent, not just matching words. Searching "How do I reset?" finds answers about "reinitialization" too.
Vector embeddings OpenAI + LanceDB for semantic search
Cohere re-ranking reduced false positives by 35%
Achieved 92% precision vs. 67% baseline keyword search
L2 distance metric for optimal similarity matching
Evaluation Framework
Every answer is tested and we know if it's correct or not.
Built custom metrics: Precision, Recall, Mean Reciprocal Rank (MRR)
AI-powered answer correctness validation using GPT-4
25 test questions with ground truth for continuous benchmarking
Automated test harness for model iteration and improvement
Production Architecture
Like LEGO blocks - swap out parts without rebuilding everything. Easy to improve and maintain.
Modular design: Indexer → Datastore → Retriever → Generator
CLI + Web interface built with Python/Reflex framework
Handles 60+ document chunks with sub-second retrieval
SQLAlchemy + Alembic for robust database management
Results & Impact
What used to take a team member half their morning now happens while their coffee is brewing.
Quantifiable Outcomes
92% Precision
89% Recall on test dataset
85% reduction in information retrieval time
0.94 Mean Reciprocal Rank for ranking quality
Business Value
Saves teams hours on documentation search
Enables instant access to knowledge
Scales to handle growing document repositories
Improves decision-making with faster insights
Tech Stack
Built with production-grade tools trusted by companies like OpenAI, Google, and Microsoft to handle real-world scale.
Technologies
Categories
Machine Learning & AI
Hands-on experimentation with fraud detection, retrieval systems, and autonomous agents.



